
大型语言模型(LLM)的性能在很大程度上取决于其预训练数据集的质量和规模。
然而,像Llama 3
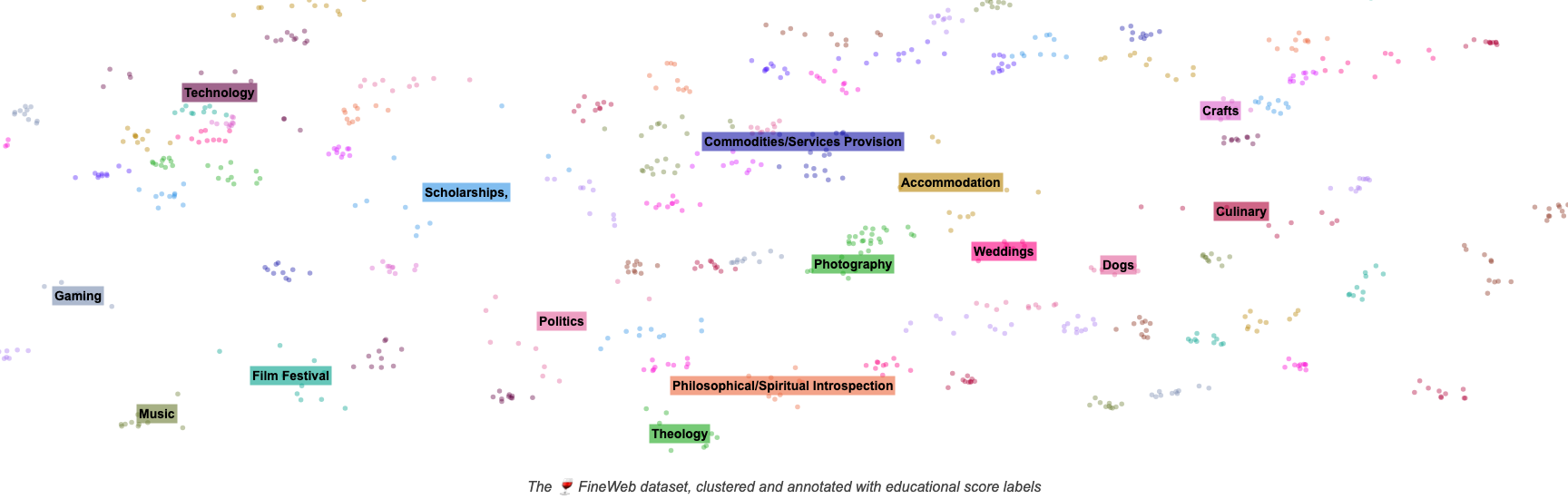
最近,我们发布了 🍷 FineWeb,这是一个新的大规模(15万亿个标记,44TB磁盘空间)的LLM预训练数据集。FineWeb源自96个 CommonCrawl 快照,并且与其他开源预训练数据集相比,使用FineWeb训练的LLM表现更优。为了让机器学习领域更加透明,并推动对如何训练高质量大型语言模型的公开理解,我们仔细记录并分析了FineWeb中使用的所有设计选择,包括对去重和过滤策略的深入研究。本长篇报告深入探讨了如何为LLM预训练创建一个大规模、高质量的网页级数据集。数据集本身🍷 FineWeb可在 此处 获取。
在本报告中,我们还介绍了 📚 FineWeb-Edu,它是FineWeb的一个子集,通过可扩展的自动化高质量教育价值标注构建而成,并且在许多教育基准测试(如MMLU、ARC和OpenBookQA)上优于所有公开可用的网页数据集。
📚 FineWeb-Edu 有两种规模/过滤级别可供选择:1.3万亿(教育内容非常高)和5.4万亿(教育内容高)个标记(所有标记均使用GPT2分词器
两个数据集均根据宽松的 ODC-By 1.0许可协议 发布。
总结: 本博客涵盖了关于大规模处理和评估数据质量的讨论,🍷 FineWeb的构建方法(列出并解释我们所有的设计选择),以及创建其📚 FineWeb-Edu子集的过程。
关于用于训练LLM的网页数据集,一个常见的问题是“他们从哪里获取所有这些数据?” 通常有两种选择:
为了构建🍷 FineWeb,我们遵循了许多LLM训练团队过去的做法,以 CommonCrawl(CC)作为起点。 非营利组织Common Crawl自2007年以来一直在抓取网页,通常每1到2个月发布一次新的抓取数据,其中包含通过自动网页抓取获得的200到400TiB的文本内容。
例如,最新的CC抓取数据(2024年4月)包含27亿个网页,总计386TiB的未压缩HTML文本内容
鉴于涉及的数据量巨大,我们必须克服的主要挑战之一是拥有一个模块化、可扩展的代码库,该代码库能够让我们快速迭代处理决策,轻松尝试新想法,同时适当地并行化工作负载,并提供对数据的清晰洞察。
为此,我们开发了 datatrovedatatrove 存储库 中找到我们使用的具体脚本。
这可能是创建数据集时需要牢记的主要问题。在大多数情况下,特别是在大型语言模型预训练的背景下
在给定的被认为“干净”的语料库(通常是维基百科
另一种比较不同数据集的方法是在每个数据集上训练一个模型,并让人类对模型的生成结果进行评分和比较(例如在 LMSYS Chatbot Arena 上)
在这项工作中,我们采用了训练小模型并在一组“早期信号”基准测试任务上对其进行评估的方法。我们认为,在牢记上述关于在评估基准上过度拟合的注意事项的情况下,这是衡量用于训练这些模型的数据质量的合理代理。
为了比较给定处理步骤的影响,我们在数据集的两个版本上训练了两个模型,一个版本应用了额外的步骤(我们希望评估的步骤),另一个版本则去除了该步骤。除了数据之外,这两个模型在其他方面完全相同:参数数量相同、架构超参数相同,并且在每个版本的数据中随机采样相同数量的标记进行单轮训练 —— 因此唯一的区别在于训练数据。然后,我们在相同的任务集上评估每个模型,并比较平均得分。
我们的消融模型使用 nanotron 进行训练。我们的“消融模型”有18.2亿个参数(包括嵌入层),使用Llama架构,序列长度为2048,全局批量大小约为200万个标记,并使用GPT2分词器。对于大多数消融实验,我们在约280亿个标记上进行训练(大致是该模型大小的Chinchilla
我们使用 lighteval 对模型进行评估。我们通过选择能够在相对较小规模(“小”模型仅在“几十亿”个标记上训练)下提供良好信号的基准测试,精心挑选了一组用于消融实验的基准测试。我们通常使用以下标准从 lighteval 中所有可用的基准测试中选择这些基准测试:
经过考虑,我们选择了以下基准测试列表:
为了确保我们的检查点评估在有限的时间内完成,我们将较长的基准测试限制在1000个样本(在单个8GPU节点上进行评估,时钟时间不到5分钟,与训练并行进行)。
在接下来的小节中,我们将解释生成FineWeb数据集所采取的每个步骤。
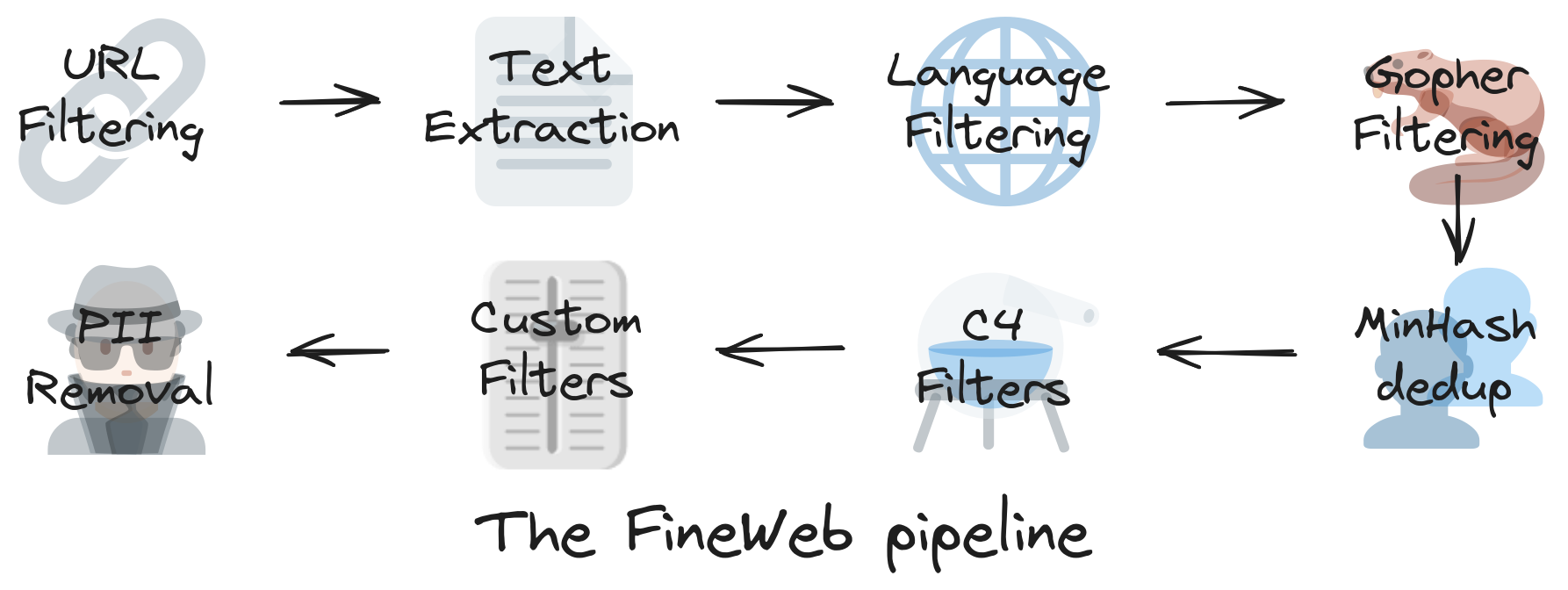
CommonCrawl数据主要有两种格式:WARC和WET。 WARC (网页存档格式)文件包含抓取的原始数据,包括完整的页面HTML和请求元数据。 WET(WARC封装文本)文件提供了这些网站的纯文本版本。
许多数据集以WET文件作为起点。根据我们的经验,Common Crawl用于创建这些WET文件的默认文本提取方法对于LLM预训练的目标来说并不理想
为了验证这一决策,我们直接使用WET文件处理了2019 - 18的转储数据,并使用trafilatura从WARC文件中提取文本进行处理favour_precision=True。
然而,需要注意的是,文本提取是我们处理过程中最耗时的步骤之一,因此我们认为对于预算较低的团队来说,使用现成的WET数据可能是一个合理的折衷方案。
过滤是数据整理过程中的重要部分。它包括去除部分数据(可以是单词、行甚至整个文档),这些数据会降低模型的性能,因此在我们以评估为驱动的数据集创建过程中被认为是“低质量”的。
作为我们过滤的基础,我们使用了RefinedWeb
在对每个提取的文本转储应用此过滤后(目前有96个转储),我们获得了大约36万亿个标记的数据gpt2 分词器进行分词后的标记数量。
去重是为LLM预训练创建大型网页数据集时最重要的步骤之一。数据集去重方法旨在识别和去除数据集中的冗余/重复数据。
网络上有许多聚合器、镜像、模板化页面或只是在不同域名和网页上传播的重复内容。有时,这些重复页面甚至可能是由抓取器本身引入的,当不同的链接指向同一页面时就会出现这种情况。
去除这些重复项(去重)与模型性能的提升
有不同的方法来识别甚至定义重复数据。常见的方法依赖于哈希技术来加速过程,或者构建高效的数据结构来索引数据(如后缀数组)。方法也可以是“模糊”的,即使用某种相似度度量将文档标记为重复项,或者是“精确”的,即检查两个文档(或行、段落或任何其他粒度级别)之间的精确匹配
遵循RefinedWeb
这意味着对于相似度(s)为0.7、0.75、0.8和0.85的两个文档,它们被识别为重复项的概率分别为56%、77%、92%和98.8%(1 - (1 - s^8)^14)。请参阅下面的图表,比较我们使用112个哈希值的设置与RefinedWeb使用9000个哈希值的设置,后者将哈希值分成450个桶,每个桶包含20个哈希值(这需要大量的计算资源,因为每个单独的哈希值都必须计算、存储并与其他文档的哈希值进行比较):
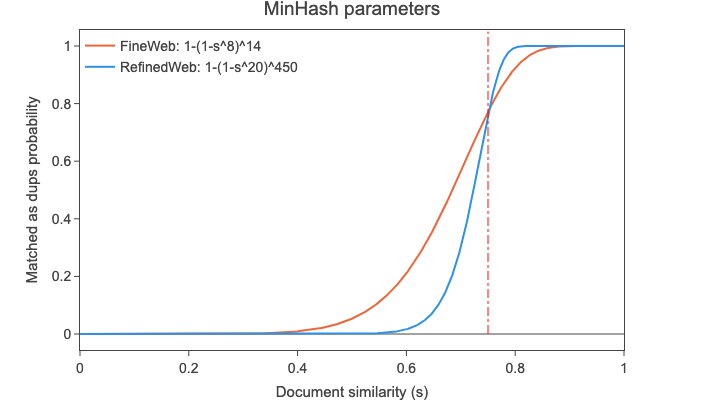
虽然RefinedWeb中大量的哈希函数允许更陡峭、更明确的截止点(实际相似度接近阈值的文档更有可能被正确识别),但我们认为计算和存储方面的节省是一个合理的折衷方案。
还需要注意的是,文档内去重已经由我们的重复过滤器处理,该过滤器会去除包含许多重复行和段落的文档。
最初,我们假设 去重越多越好,因此我们的第一种方法是将整个数据集(所有90多个转储)作为一个大的数据集一起进行去重,使用MinHash。
我们以迭代的方式进行:从最近的转储(当时是2023 - 50)开始,按时间顺序进行,直到我们处理完最旧的抓取数据。我们不仅对每个转储内部进行去重,还去除与之前处理过的转储中的任何文档匹配的文档。
例如,对于第二近的转储(当时是2023 - 40),我们除了对其内部进行去重外,还将其与最近的转储进行去重。因此,转储越旧,与之进行去重的转储数量就越多,从其中去除的数据也就越多(实际上,在最旧的转储中,去重步骤去除了超过90%的基础过滤数据)。
以这种方式对数据集进行去重后,得到了4万亿个标记的数据,但令我们非常惊讶的是,当在随机采样的3500亿个标记子集上进行训练时,我们的消融模型与在未去重数据上训练的模型相比几乎没有改进,在我们的综合任务上的得分远低于其前身RefinedWeb(见下图)。
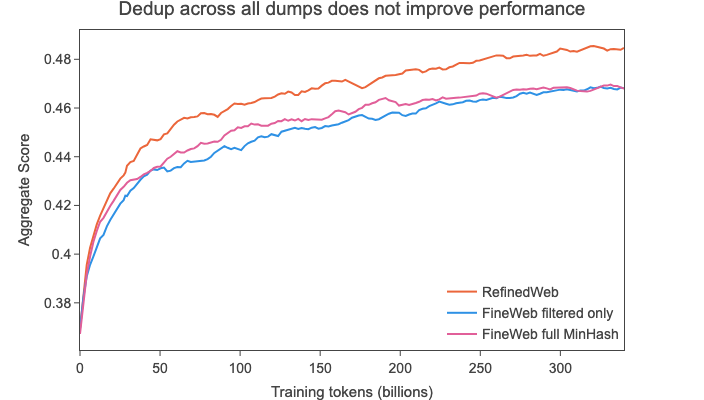
这挑战了我们认为更多去重必然会导致更高基准测试得分的假设,因此我们决定仔细研究最旧的转储之一,即2013 - 48转储:
作为一个实验,我们尝试在从2013 - 48转储中采样的280亿个标记上训练两个模型:
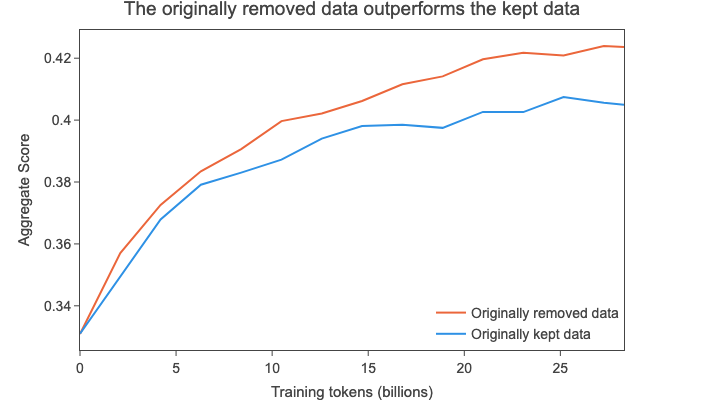
这些结果表明,对于这个单独考虑的较旧转储,保留的数据(原始数据的10%)实际上比我们去除的90%的数据 更差
我们决定尝试一种替代方法:我们使用MinHash对每个转储进行单独去重(独立于其他转储)。这得到了20万亿个标记的数据。
当在该数据集的随机样本上进行训练时,我们发现它现在与RefinedWeb的性能相当(见下图):
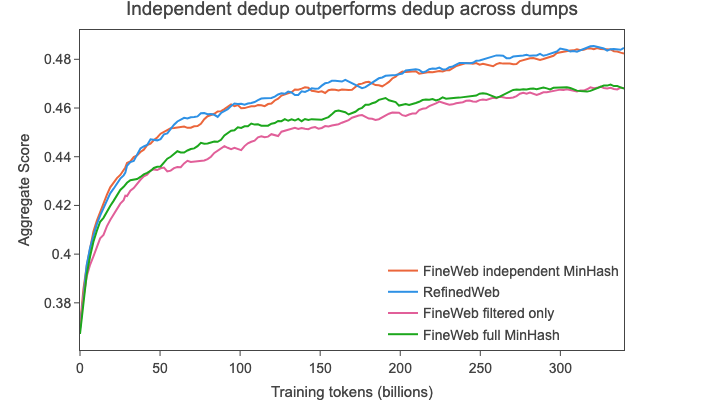
我们假设去重带来的主要改进是去除了每个转储中都存在的非常大的聚类(您可以在RefinedWeb论文中找到这些聚类的一些示例,每个聚类包含 数十万个 文档),而对重复项数量较少(少于约100,即转储的数量)的聚类进行进一步去重实际上会损害性能:在任何其他转储中都找不到重复匹配项的数据实际上可能质量较差/分布较偏离(如2013 - 48数据的结果所示)。
虽然在对几个转储一起进行去重时可能会看到一些性能提升,但在整个数据集(所有转储)的规模上,这种低质量数据上采样的副作用似乎更具影响力。
一种可能的情况是,随着过滤质量的提高,这种影响可能不会那么明显,因为过滤可能能够去除一些低质量数据。我们还尝试在单独去重的转储基础上应用不同的、通常是“更轻量级”的去重方法。您可以在下面进一步了解这些方法。
由于去重的性质,其效果在数据集的较小切片中(如280亿个标记,我们用于过滤消融实验的大小)并不总是很明显。此外,必须考虑到在对所有CommonCrawl转储进行去重时存在特定的影响,因为有些URL/页面会从一个转储重新抓取到下一个转储。
为了可视化训练标记数量的扩展对测量去重影响的影响,我们考虑了以下(关于观察到的重复程度非常极端且不现实的)理论场景:
然后,我们模拟从这个20万亿个标记的整个数据集中均匀采样文档,以获得10亿、100亿、1000亿、3500亿和1万亿个标记的子集。在下面的图像中,您可以看到每个文档会被重复的频率。
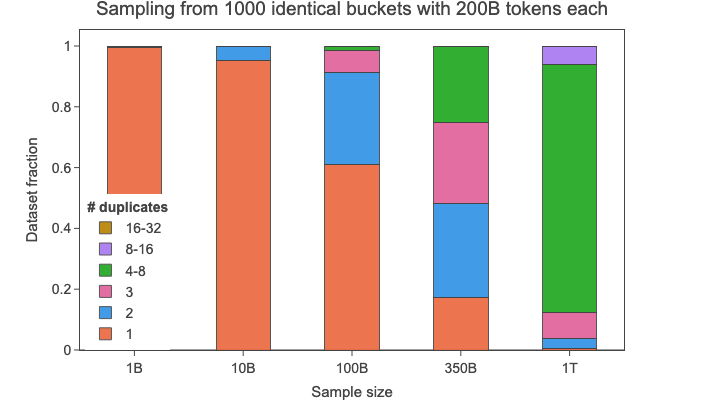
对于10亿个标记,几乎所有文档都是唯一的(重复次数 = 1),尽管在整个数据集中每个文档重复了100次(每个转储一次)。我们在1000亿个标记的规模(占总数据集的0.5%)开始看到一些变化,有大量文档重复了两次,甚至有一些重复了4 - 8次。在1万亿个标记的更大规模(占总数据集的5%)上,大多数文档重复了多达8次,有些甚至重复了多达16次。
我们在3500亿个标记的规模上对去重后的数据进行了性能评估,根据这个理论场景,该规模的数据将包含大量重复多达8次的文档。这个模拟说明了在去除最大的重复聚类后,测量去重对LLM训练影响的固有困难。
为了在我们新发现的方法(独立对每个转储进行去重)的基础上进行改进,我们尝试通过使用替代的全局(对所有转储)去重方法对独立进行MinHash去重后的20万亿个标记的数据进行进一步去重。我们探索了以下方法:
在这些方法处理后的数据上训练的模型的性能始终比原始独立去重数据的性能差(尽管程度不同):
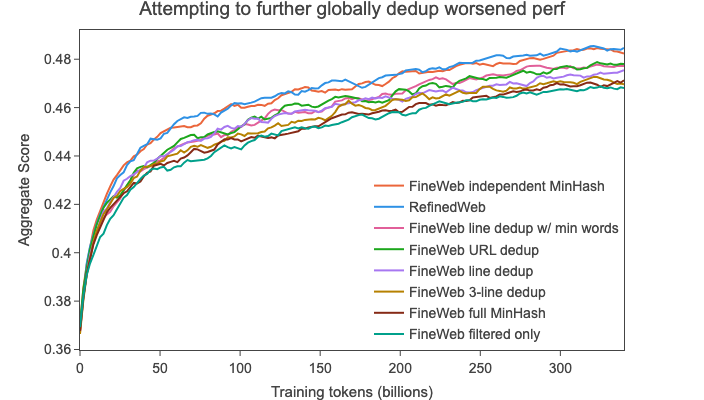
到目前为止,我们使用基础过滤和独立MinHash已经达到了我们试图重现和扩展的先前工作RefinedWeb的相同性能。然而,在我们的综合任务中,另一个经过大量过滤的数据集C4
因此,我们着手寻找新的过滤步骤,首先是为了达到C4的性能,然后是超越它。一个自然的起点是研究C4本身的处理过程。
C4数据集 于2019年首次发布。它是从 2019 - 18 CommonCrawl转储中获得的,通过去除非英文数据、在行和文档级别应用一些启发式过滤、在行级别进行去重以及去���包含黑名单单词的文档。
尽管它的历史悠久且对于当前标准来说规模有限(约1750亿个gpt2标记),但这个数据集至今仍然是典型LLM训练的常见子集,被用于相对较新的Llama1
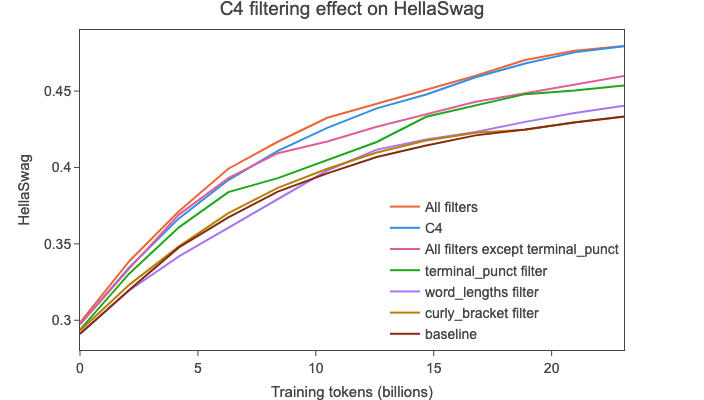
{ 的文档)使我们能够达到C4在HellaSwag上的性能(分别为“所有过滤器”和“C4”曲线)。
我们决定应用上述所有C4过滤器,但不包括终端标点过滤器。我们通过更长时间的运行验证了这些结果,您可以在下一节的图表中找到相关内容。
为了开发新的启发式过滤器并选择其阈值,我们设计了一个系统的过程:
由于我们(新的)假设是全局MinHash会极大地提升最旧转储中低质量数据的比例,我们计算了2013 - 48和2015 - 22抓取(两个较旧的抓取)的独立MinHash和(质量较差的)全局MinHash版本的指标。然后,我们通过查看每个版本的这些指标的分布,从宏观层面比较了统计数据。
也许并不太令人惊讶的是,鉴于我们在去重方面的发现,我们发现两种去重方法在大多数指标上存在显著差异。例如,行字符重复率 指标(重复行中的字符数 / 字符总数)从独立去重(2015 - 22为0.0053,2013 - 48为0.0058)到全局去重(2015 - 22为0.011,2013 - 48为0.01)大致翻了一番,这表明后者的文档间重复率更高。
按照上述过程对这些数据集进行处理后,得到了 十七 个候选指标 - 阈值对。在下面的图像中,您可以看到其中三个直方图:
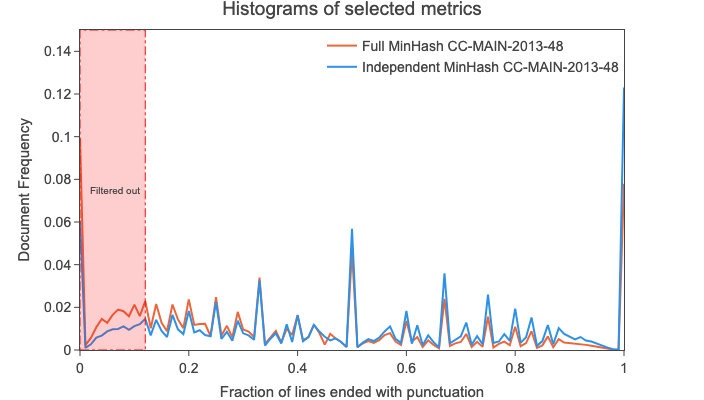
例如,我们检查了“以标点符号结尾的行的比例”的直方图(见上图),并观察到全局MinHash在约0.12处的文档密度增加。 然后,我们使用这个阈值进行过滤,发现去除的数据中包含大量短列表或仅由文档布局文本(如“主页”、“注册”等)组成。
然后,我们通过在 2019 - 18抓取 上进行几次 280亿个标记 的消融实验,评估了这十七个新创建的过滤器的有效性。在所有这些实验中,我们确定了 三个 过滤器(基于上图的直方图)在综合得分上表现出最显著的改进:
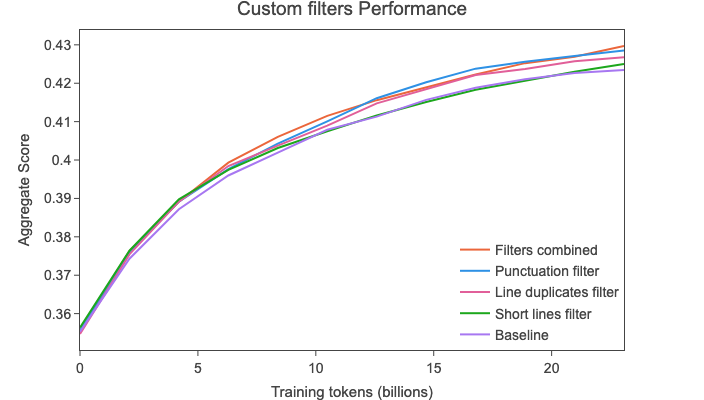
这些过滤器使我们能够进一步提高性能,特别是超越了C4数据集的性能,同时提供了一个更大的数据集。
最终的 🍷 FineWeb 数据集包含15T标记,并按顺序包括以下先前提到的步骤,每个步骤都在我们的基准测试任务组上提供了性能提升:
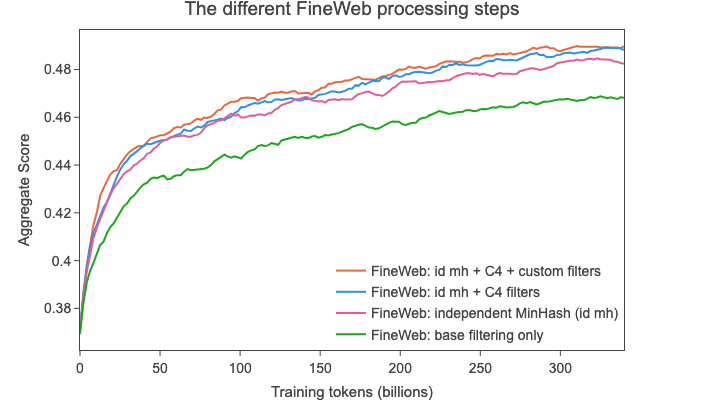
我们将 🍷 FineWeb 与以下通常被认为是最高质量的公开可用网页级数据集进行了比较(我们还为每个数据集指出了其公开版本中的近似标记数量):
您可以在 此集合 中找到公开可用的3500亿标记训练的消融模型。我们在每1000个训练步骤上传了检查点。您还可以在 此处 找到我们的完整 评估结果。
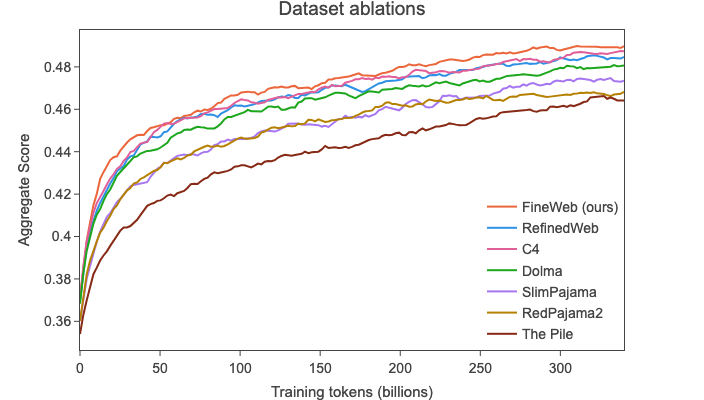
据我们所知,🍷 FineWeb是目前能够实现最高模型性能,同时允许在数万亿个标记上进行训练的开源数据集。
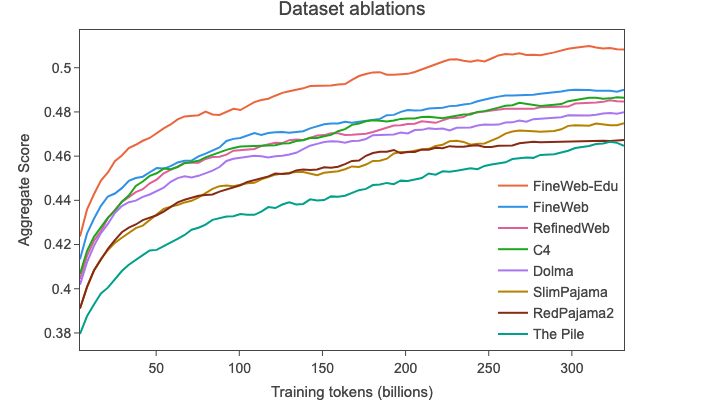
📚 FineWeb-Edu 是FineWeb的一个额外发展,我们很高兴在本技术报告中介绍并公开发布它。📚 FineWeb-Edu基于一种最近出现的过滤LLM训练数据集的新方法:使用合成数据开发用于识别教育内容的分类器。这种技术在Llama 3
流行的Phi3模型在3.3万亿和4.8万亿个标记上进行训练,论文
我们的训练数据包括经过大量过滤的公开可用网页数据(根据“教育水平”),这些数据来自各种开放的互联网来源,以及合成的LLM生成数据。
同样,Llama 3博客文章
我们发现,前几代Llama擅长识别高质量数据,因此我们使用Llama 2来帮助构建驱动Llama 3的文本质量分类器。
然而,这些分类器和过滤后的数据集并未公开。为了进一步提高🍷 FineWeb的质量,我们使用 Llama - 3 - 70B - Instruct 生成的注释开发了一个教育质量分类器,以创建 📚 FineWeb-Edu。
我们使用 Llama - 3 - 70B - Instruct 对🍷 FineWeb中的50万个样本进行了注释,为每个样本的教育质量从0到5进行评分。
我们探索了各种提示格式,以使用LLM自动提取教育得分,并发现袁等人

在选择用于注释数据的开源权重模型方面,我们尝试了几种模型,包括 Mixtral - 8x7B - Instruct 和 Mixtral - 8x22B - Instruct、Llama - 3 - 70B - Instruct,以及一个综合这三个模型得分的评审团
为了将我们的注释扩展到FineWeb中的数万亿个标记,我们使用Llama3 - 70B的注释来训练一个小分类器。我们使用的模型是 Snowflake - arctic - embed 嵌入模型,其上有一个带有单个回归输出的分类头。我们在45万个Llama 3注释上对该模型进行了20个epoch的训练,学习率为3e - 4,冻结了嵌入层和编码器层。我们保存了在我们保留的4.5万个样本验证集上F1得分最高的检查点,将Llama 3的注释视为真实标签。训练后,我们将得分四舍五入为从 0 到 5 的整数。
然后,我们通过使用一个固定阈值来确定一个文件是否具有教育性,将问题转换为一个二分类任务。使用阈值 3 时,模型在验证集上的F1得分达到了82%,表明在区分高质量教育内容方面表现出色。
分类器可在 HuggingFaceFW/fineweb - edu - classifier 找到。训练和推理代码可在 GitHub 上找到。
我们将分类器应用于🍷 FineWeb的15T标记,这一过程需要6000个H100 GPU小时。我们研究了使用不同过滤阈值的影响,发现使用阈值 3 得到的整体结果最佳。尽管使用高于 3 的阈值可以提高在知识和推理密集型基准测试上的性能,但会显著降低在HellaSwag和PIQA上的性能。下图显示了每个阈值与FineWeb在六个不同基准测试上的性能比较;它使用了一个在80亿个标记上训练的18.2亿参数模型。
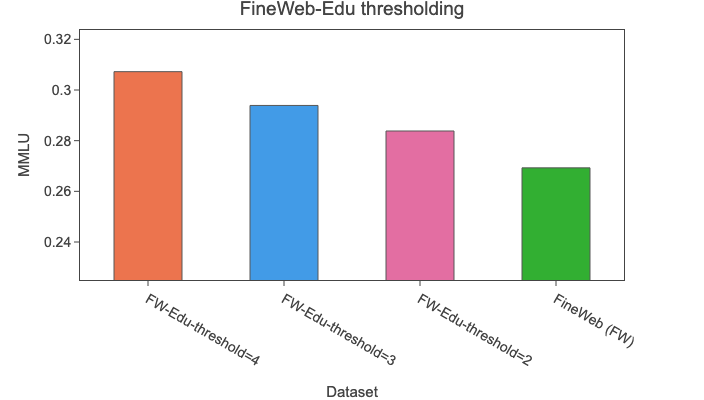
注意: 此消融实验是在FineWeb和FineWeb - Edu子集的2024 - 10转储的80亿个标记上进行的,这可能不能代表整个数据集。下一个消融实验表明,阈值3的结果在从所有FineWeb转储中选取的3500亿个标记的更长运行中仍然成立,但在HellaSwag上,我们注意到性能略有下降。
我们通过过滤掉得分低于3的样本构建了 📚 FineWeb - Edu。这去除了92%的数据集,剩下1.3万亿个教育标记。 为了在更大规模上评估这种过滤的有效性,我们使用一个18.2亿参数的模型在3500亿个标记上进行了消融实验,类似于上面提到的FineWeb过滤消融实验:
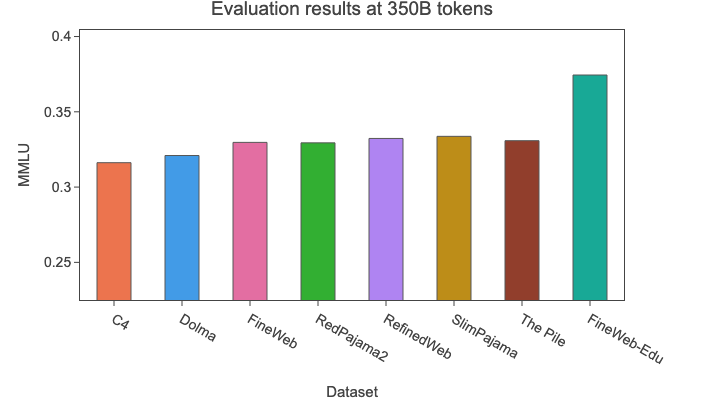
以下是上述消融实验结果的关键亮点:
鉴于阈值2也表现出了较强的性能,同时保留了更多的数据,我们发布了一个使用该阈值过滤的额外数据集,包含5.4万亿个标记,可在 HuggingFaceFW/fineweb - edu - score - 2 找到。
您可以在 此集合 中找到这两个数据集以及用于过滤的分类器。
就像美酒一样,并非所有的抓取数据都是一样的。
在进行过滤步骤的消融实验时,我们注意到某些抓取数据的性能明显优于其他数据。我们决定对此现象进行研究。
对于每个抓取数据,我们在从该抓取数据(经过基础过滤和MinHash去重步骤后)中随机采样的270亿个标记上训练了两个18亿参数的模型,每次运行使用不同的随机270亿标记采样。我们总共训练了192个这样的模型,总计超过6万个H100 GPU小时。然后,我们取两次运行的最后3个检查点,并绘制每个抓取数据的这6个数据点的平均值。
下图清楚地显示,一些转储数据的性能远低于其他数据。每年用不同的颜色表示,每年的抓取次数也不同。
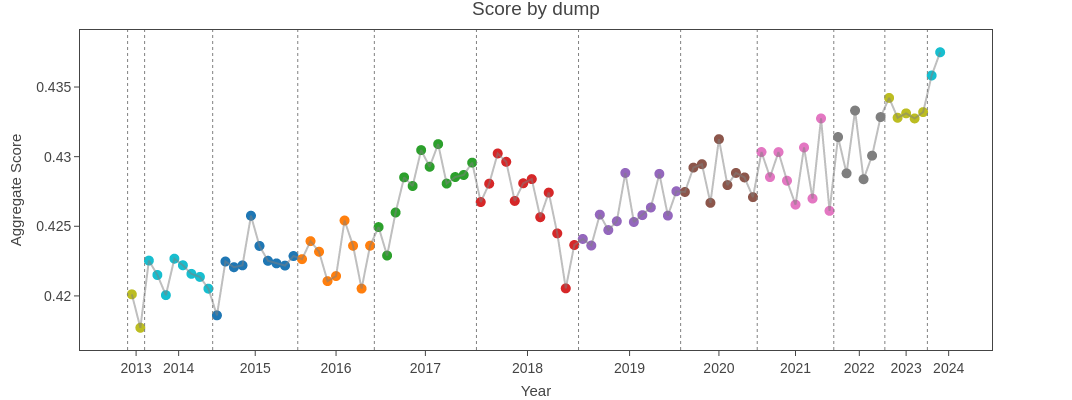
我们研究了这种行为的可能原因,例如每个转储中最常见URL的变化以及潜在的基准测试污染,但未能找到确凿的解释。我们将进一步的研究留待未来的工作。
我们想知道最近几个抓取数据的强性能是否部分归因于更大数量的合成数据(由LLM生成的数据)的存在。由于最近LLM(特别是ChatGPT)的普及,这种变化并不令人惊讶。
据我们所知,目前没有万无一失的方法来检测合成数据,因此我们选择使用一个代理指标:我们测量了每个抓取数据中以下单词的频率: "深入研究", "作为一个大型语言模型", "需要注意的是", "丰富的织锦",
"相互交织", "当然!", "深入探讨",所有这些都是ChatGPT常用的词汇。
需要注意的是,并非所有包含这些短语之一的样本都一定是由ChatGPT生成的(而且许多ChatGPT生成的样本也不包含这些短语),但假设合成数据的数量在不同的抓取数据中保持不变,我们预计这些频率在时间上大致保持恒定。
结果如下所示:
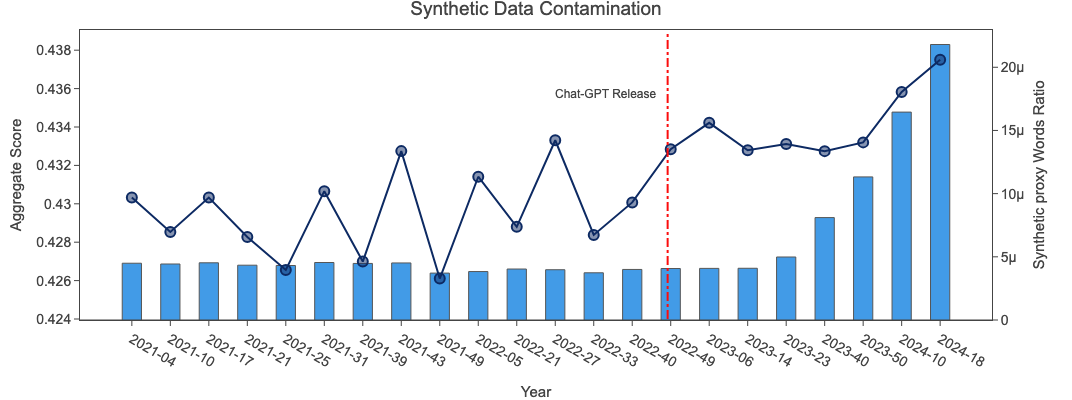
虽然频率在2023 - 14之前大致保持恒定(ChatGPT于2022年底发布),但我们发现最近的抓取数据中我们的代理指标急剧增加。虽然这个简单的测试不足以得出ChatGPT完成结果和其他合成数据正在提高最近抓取数据质量的结论,但至少它似乎没有对其造成严重损害。
我们预计新的CC抓取数据中将继续出现越来越多的合成数据。然而,虽然对于相对较小的训练来说,这些数据似乎不会损害性能(甚至可能会提高性能),但对于更大规模的训练来说,情况是否仍然如此尚不清楚。
通过我们的开放科学努力,我们希望继续揭示高性能大型语言模型训练这个黑匣子,并使每个模型训练者都能够创建最先进的LLM。我们很高兴继续对FineWeb进行迭代,并以完全开放和可重现的方式发布经过不断改进的网页数据过滤子集。
短期内,我们期待将(英语)FineWeb的经验应用到其他语言上。虽然英语目前在LLM领域占据主导地位,但我们相信,尽可能让其他语言的高质量网页数据变得易于获取将产生巨大的影响。
简而言之:研究大规模和开放环境下创建数据集的科学的未来是光明而令人兴奋的 🤗。
在学术环境中进行引用时,请将此工作引用为
佩内多等人,《FineWeb数据集:大规模提炼网页以获取优质文本数据》,2024年。
BibTeX引用
@inproceedings{
penedo2024the,
title={The FineWeb Datasets: Decanting the Web for the Finest Text Data at Scale},
author={Guilherme Penedo and Hynek Kydl{\'\i}{\v{c}}ek and Loubna Ben allal and Anton Lozhkov and Margaret Mitchell and Colin Raffel and Leandro Von Werra and Thomas Wolf},
booktitle={The Thirty-eight Conference on Neural Information Processing Systems Datasets and Benchmarks Track},
year={2024},
url={https://openreview.net/forum?id=n6SCkn2QaG}
}